
| 創澤機器人 |
| CHUANGZE ROBOT |
隨著移動互聯網、IoT、5G 等的應用和普及,一步一步地我們走進了數字經濟時代。隨之而來的海量數據將是一種客觀的存在,並發揮出越來越重要的作用。時序數據是海量數據中的一個重要組成部分,除了挖掘分析預測等,如何高效的壓縮存儲是一個基礎且重要的課題。同時,我們也正處在人工智能時代,深度學習已經有了很多很好的應用,如何在更多更廣的層麵發揮作用?本文總結了當前學術界和工業界數據壓縮的方法,分析了大型商用時序數據壓縮的特性,提出了一種新的算法,分享用深度強化學習進行數據壓縮的研究探索及取得的成果。
深度學習的本質是做決策,用它解決具體的問題時很重要的是找到契合點,合理建模,然後整理數據優化 loss 等最終較好地解決問題。在過去的一段時間,我們在用深度強化學習進行數據壓縮上做了一些研究探索並取得了一些成績,已經在 ICDE 2020 research track 發表(Two-level Data Compression using Machine Learning in Time Series Database)並做了口頭彙報。在這裏做一個整體粗略介紹,希望對其它的場景,至少是其它數據的壓縮等,帶來一點借鑒作用。
背景描述
1 時序數據
時序數據顧名思義指的是和時間序列相關的數據,是日常隨處可見的一種數據形式。下圖羅列了三個示例:a)心電圖,b)股票指數,c)具體股票交易數據。
關於時序數據庫的工作內容,簡略地,在用戶的使用層麵它需要響應海量的查詢,分析,預測等;而在底層它則需要處理海量的讀寫,壓縮解壓縮,采用聚合等操作,而這些的基本操作單元就是時序數據
可以想象,任何電子設備每天都在產生各種各樣海量的時序數據,需要海量的存儲空間等,對它進行壓縮存儲及處理是一個自然而然的方法。而這裏的著重點就是如何進行更高效的壓縮。
2 強化學習
機器學習按照樣本是否有 groundTruth 可分為有監督學習,無監督學習,以及強化學習等。強化學習顧名思義是不停地努力地去學習,不需要 groundTruth,真實世界很多時候也沒有 groundTruth,譬如人的認知很多時候就是不斷迭代學習的過程。從這個意義上來說,強化學習是更符合或更全麵普遍的一種處理現實世界問題的過程和方法,所以有個說法是:如果深度學習慢慢地會像 C/Python/Java 那樣成為解決具體問題的一個基礎工具的話,那麼強化學習是深度學習的一個基礎工具。
強化學習的經典示意圖如下,基本要素為 State,Action,和 Environment。基本過程為:Environment 給出 State,Agent 根據 state 做 Action 決策,Action 作用在 Environment 上產生新的 State 及 reward,其中 reward 用來指導 Agent 做出更好的 Action 決策,循環往複….
而常見的有監督學習則簡單很多,可以認為是強化學習的一種特殊情況,目標很清晰就是 groudTruth,因此對應的 reward 也比較清晰。
強化學習按照個人理解可以歸納為以下三大類:
1)DQN
Deep Q network,比較符合人的直觀感受邏輯的一種類型,它會訓練一個評估 Q-value 的網絡,對任一 state 能給出各個 Action 的 reward,然後最終選擇 reward 最大的那個 action 進行操作即可。訓練過程通過評估 “估計的 Q-value” 和 “真正得到的 Q-value” 的結果進行反向傳遞,最終讓網絡估計 Q-value 越來越準。
2)Policy Gradient
是更加端到端的一種類型,訓練一個網絡,對任一 state 直接給出最終的 action。DQN 的適用範圍需要連續 state 的 Q-value 也比較連續(下圍棋等不適用這種情況),而 Policy Gradient 由於忽略內部過程直接給出 action,具有更大的普適性。但它的缺點是更難以評價及收斂。一般的訓練過程是:對某一 state,同時隨機的采取多種 action,評價各種 action 的結果進行反向傳遞,最終讓網絡輸出效果更好的 action。
3)Actor-Critic
試著糅合前麵兩種網絡,取長補短,一方麵用 policy Gradient 網絡進行任一 state 的 action 輸出,另外一方麵用 DQN 網絡對 policy gradient 的 action 輸出進行較好的量化評價並以之來指導 policy gradient 的更新。如名字所示,就像表演者和評論家的關係。訓練過程需要同時訓練 actor(policy Graident)和 critic(QN)網絡,但 actor 的訓練隻需要 follow critic 的指引就好。它有很多的變種,也是當前 DRL 理論研究上不停發展的主要方向。
時序數據的壓縮
對海量的時序數據進行壓縮是顯而易見的一個事情,因此在學術界和工業界也有很多的研究和探索,一些方法有:
Snappy:對整數或字符串進行壓縮,主要用了長距離預測和遊程編碼(RLE),廣泛的應用包括 Infuxdb。
Simple8b:先對數據進行前後 delta 處理,如果相同用RLE編碼;否則根據一張有 16 個 entry 的碼表把 1 到 240 個數(每個數的 bits 根據碼表)pack 到 8B 為單位的數據中,有廣泛的應用包括 Infuxdb。
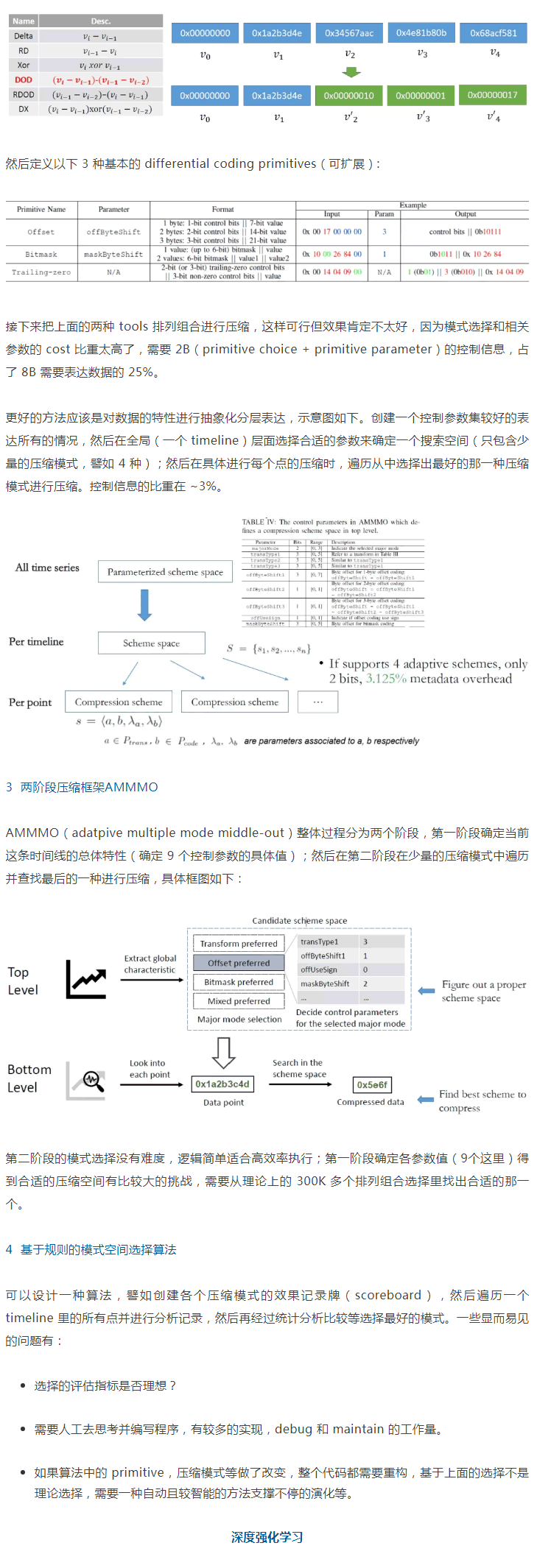
Compression planner:引入了一些 general 的壓縮 tool 如 scale, delta, dictionary, huffman, run length 和 patched constant 等,然後提出了用靜態的或動態辦法組合嚐試這些工具來進行壓縮;想法挺新穎但實際性能會是個問題。
ModelarDB:側重在有損壓縮,基於用戶給定的可容忍損失進行壓縮。基本思想是把維護一個小 buff,探測單前數據是否符合某種模式(斜率的直線擬合),如果不成功,切換模式重新開始buff等;對支持有損的 IoT 領域比較合適。
Sprintz:也是在 IoT 領域效果會比較好,側重在 8/16 bit 的整數處理;主要用了 scale 進行預測然後用 RLC 進行差值編碼並做 bit-level 的 packing。
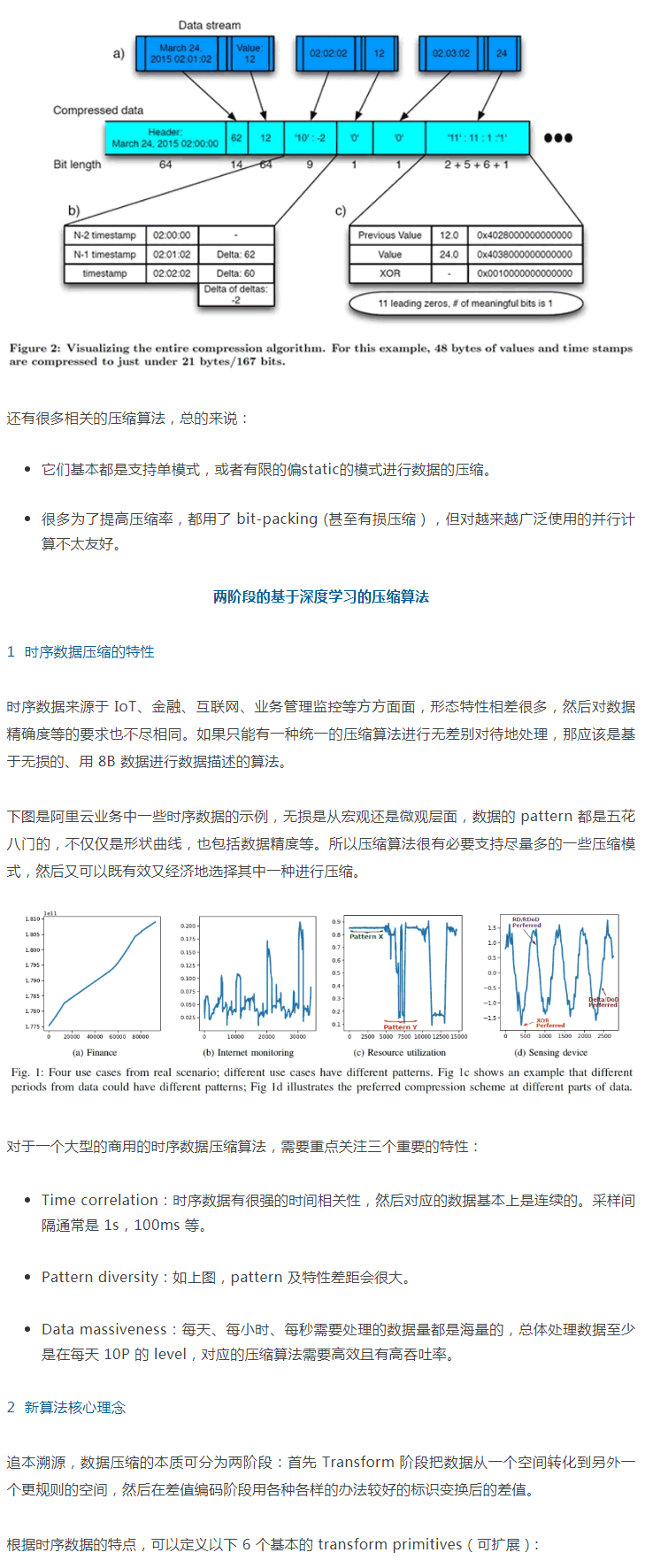
Gorilla:應用在 Facebook 高吞吐實時係統中的當時 sofa 的壓縮算法,進行無損壓縮,廣泛適用於 IoT 和雲端服務等各個領域。它引入 delta-of-delta 對時間戳進行處理,用 xor 對數據進行變換然後用 Huffman 編碼及 bit-packing。示例圖如下所示。
MO:類似 Gorilla,但去掉了 bit-packing,所有的數據操作基本都是字節對齊,降低了壓縮率但提供了處理性能。

 |
| 機器人招商Disinfection Robot機器人公司機器人應用智能醫療物聯網機器人排名機器人企業機器人政策教育機器人迎賓機器人機器人開發獨角獸消毒機器人品牌消毒機器人合理用藥地圖 |


